- 종속변수와 관련이 있는 독립변수를 찾을 때, 또 독립변수들 간의 관계를 이해하고자 할 때 사용
- 가격, 주가, 수량 등 연속적인 값을 갖는 연속 변수를 예측하는데 주로 활용
□ 종류
- 단순회귀분석 : 하나의 종속변수와 하나의 독립변수 사이의 관계를 분석할 때
- 다중회귀분석 :하나의 종속 변수와 여러 독립변수 사이의 관계를 규명하고자 할 때
■ 선형관계
: 독립변수가 종속변수에 영향을 준다면 두 변수 사이에 선형관계가 있다고 할 수 있음
ex) 속도와 거리, 섭씨와 화씨, 지름과 원의 둘레, 온도와 아이스크림 판매 수, 소득 증가에 따른 소비의 증가
■ 회귀분석 모델
□ 목적
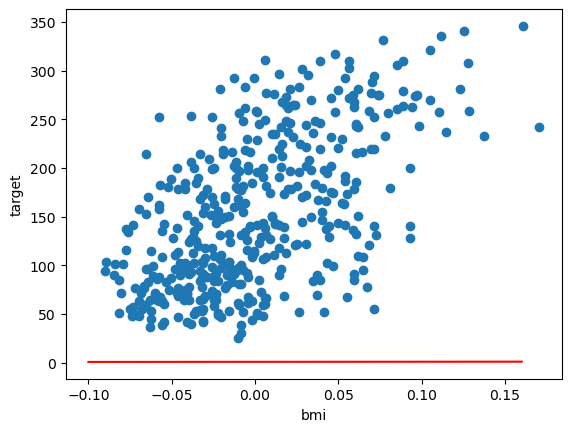
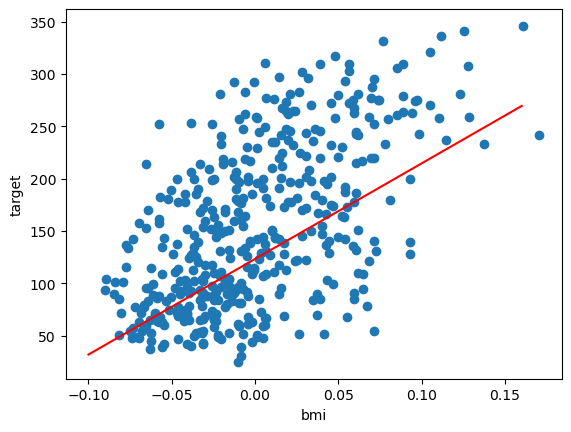
- 독립변수와 종속변수 데이터가 주어졌을 때, 두 변수의 관계를 설명할 수 있는 y=wx+b 라는 선형 관계를 찾는 것
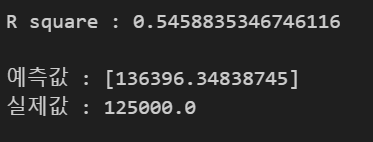
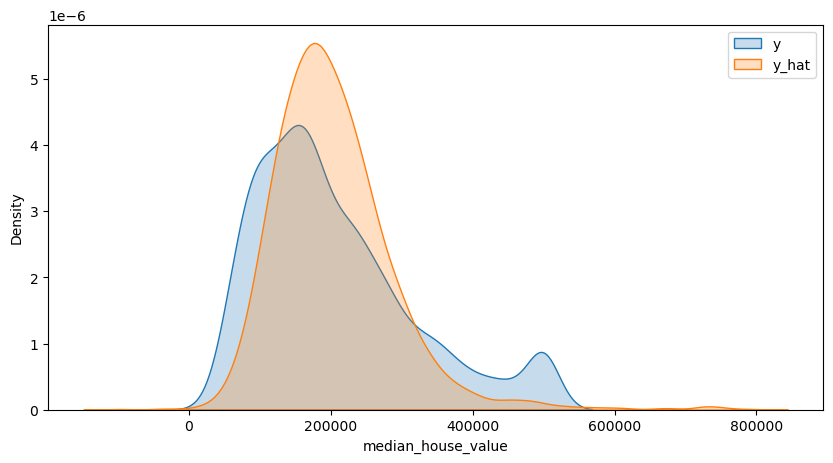
- 이와 같은 선형관계를 알고 있다면, 새로운 x값이 주어졌을 때 종속변수 y의 값을 예측할 수 있음
- 최소제곱법을 통해 오차를 최소화할 수 있는 w(가중치)와 b(오차)를 찾음
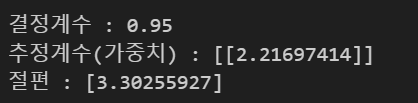
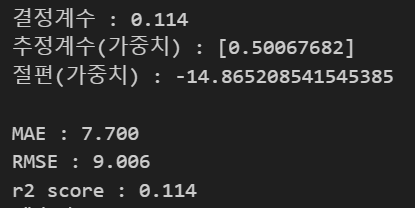
- 회귀식 (모델) : y = wx + b
- 최소제곱법 : 회귀선과 관측값들의 잔차를 제곱하여 더한 값으로 그 값이 최소가 되도록 회귀계수를 구하는 것
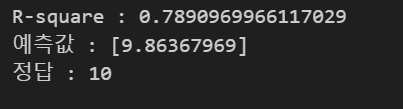
- 설명력 지표 : 피어슨 상관계수, 결정계수 R^2
□ 최소 제곱법
: 오차의 제곱의 합
※ 오차를 측정하는 방법으로 대표적으로 절댓값과 최소제곱법이 있는데, 절댓값을 사용하지 않는 이유
① 오차를 더 크게 보이게 하기 위한 목적으로 제곱법을 사용함
② 오차가 최소인 기울기 값을 찾기 위해서는 미분을 해야함. 미분을 통해 최적의 기울기를 구해야 하는데 절댓값 즉, 상수를 미분하면 0이기 때문에 미분가능한 함수를 사용하기 위해 최소제곱법을 사용함.
□ 오차함수
: 각 독립변수 별 오차를 계산하는 함수
- 실제 처리해야 하는 데이터는 다변량임.
- 데이터를 학습을 시킨 후 최적화된 가중치와 절편으로 모델을 만들어야 함.
- 예측값 : 실제 나온 값
- 오차 : 실제 나온 값과 예측값의 차이
- 가중치를 통해 각각의 레코드(사례) 별로 오차를 하나씩 다 찾아내야 함. (1개의 단위 : 1 epoch)
□ MSE
: 비용함수 (평균 제곱오차) , 2차 함수의 형태를 띔 (아래로 볼록한 모형)
- 목적
: MSE의 값이 최소가 되게 하는 값을 찾는 것
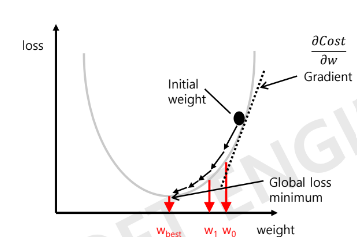
- 방법 : 경사하강법
○ 경사를 타고 내려오는 것 ○ 초기의 가중치 값은 임의로 주어짐 (시스템 내부에서 주어진 데이터 기반으로 임의의 값을 설정함) ○ 현재의 위치(비용 곡선의 한 점)에서 미분하여 기울기(가중치) 찾음 ○ 기울기가 +인지 -인지 확인
if 기울기 > 0 : 가중치 감소시켜야 함 if 기울기 < 0 : 가중치 증가시켜야 함
▷ 가중치의 값을 조절함으로써 손실 즉 오차의 범위를 줄임 ▷ 손실 최적화점을 찾아야 함
=> new Weight = old Weight - (학습률(이동거리))* 기울기
: 가중치 업데이트시, 기울기>0 : 가중치 감소함, 기울기<0 : 가중치 증가함
※ 학습률(Learning Rate) 및 이동거리
(기울기만으로 가중치를 조정한다면, 이동폭이 아주 크거나 미미할 수 있기 때문에 적절한 값을 곱할 필요가 있음)
- 경사를 타고 내려오는 보폭이라고 정의할 수 있음 - training되는 양 또는 단계 - 학습데이터를 기반으로 학습 모델 오차에 대한 가중치를 업데이트할 때 사용되는 기준점 중 하나 - 모델이 학습을 진행할 때 각각의 가중치를 얼마나 업데이트할지 결정하는 하이퍼 파라미터 - 매개변수 업데이트 시의 크기를 조절하며 모델이 적절한 방향으로 수렴할 수 있도록 도와줌 - 즉, 가중치 업데이트 크기를 결정하는 요소 - 적절한 학습률을 찾는 것이 중요함. 학습률이 너무 높으면 결과 속도가 빨라지지만 오류값을 제대로 산출해내지 못하거나 오버플로우가 발생할 수 있고, 반대로 학습률이 너무 낮으면 산출되는 결과 속도가 느려지고 오류값이 너무 많아져서 실행과정 자체가 멈줄 수 있음.
※ 오차 제곱에 대한 평균을 하는 이유 : 오차는 각 사례들에 대한 것임. 사례의 개수가 많아질수록 오차에 대한 데이터도 많아지고 범위도 커질 것이기 때문에 평균을 내서 오차를 파악하는 것임
비용함수
# Cost Function : 오차 제곱 평균 함수
# w : 가중치 (초기 : 임의값)
# x : 독립변수 (리스트)
# y : 종속변수 (리스트)
# b : 절편 (초기 : 임의값)
defMSE(w,x,y,b):
s=0
foriinrange(len(x)) : # 원소 개수 만큼 반복문 돌림
s+=(y[i]-(w*x[i]+b))**2
returns/len(x) # 오차 제곱의 평균
# y = 2x + 0.1
x= [1.,2.,3.] # 독립변수, Feature
y= [2.1,4.1,6.1] # 종속변수, Label
b=0.1
w_val= [] # 가중치 저장할 리스트
cost_val= [] # 비용함수 저장할 리스트
forwinnp.linspace(-4,8,20): # .linspace() : 균등분배 => -4~8까지 임의로 20개 균등 분배한 값
c=MSE(w,x,y,b)
w_val.append(w)
cost_val.append(c)
### cost 값을 이용한 그래프 그리기
plt.plot(w_val,cost_val)
plt.xlabel('Weight')
plt.ylabel('Cost')
plt.show() # w 값이 2일 때 최적
가중치 학습
fromsklearn.datasetsimportload_diabetes# 당뇨병관련 데이터들이 딕셔너리 형태로 저장되어 있음(기본 모듈)