[ML] 과적합 방지 - 교차 검증
■ 교차검증(Cross Validation)
: 데이터를 분할하여 모델 생성 및 적용에 번갈아 가면서 일반화하는 모델 검증 결과 평가 방법 (과적합 판단)
1. K-fold cross validation
- 자료를 k개로 분류하고 (k-1)개를 Training data, 1개를 Validation data로 구분하여 모델 생성 과정을 k번 검증 수행
- kFold(sklearn.model_selectioin패키지의 클래스): 데이터 셋을 순서대로 일정한 간격으로 분할하기 때문에 분류 분석일 경우 종속 변수 데이터의 분포가 치우칠 수 있음 ( ※ shuffle 매개변수를 True로 지정하여 임의 추출로 해결)
-일반적으로 회귀분석에서 사용함
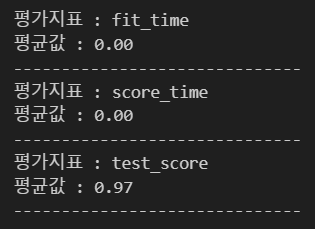
교차검증 실시하지 않은 경우
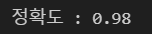
K-Fold cross validation

결과를 통해 , 위의 교차 검증은 150개의 데이터에 대해 폴드 수를 5로 설정하였고, 인덱스의 순서대로 30개(150/3)씩 검증 데이터로 설정하여 교차 검증을 수행함을 알 수 있음. 이러한 방식을 분류분석에서 사용한다면 종속변수의 값이 하나의 값으로 몰릴 것이므로 분류 분석 검증에는 적합하지 않음. (그럼에도 불구하고 사용하고자 한다면 KFold 클래스 선언 시 shuffle 파라미터를 성정하는 방법이 있긴 함.) 또한, 교차 검증 후 평균 정확도가 0.913인데, 검증 전 모델의 정확도는 0.98이므로 모델이 과적합함을 알 수 있음.
2. Stratified K-fold cross validation
- 원본 데이터의 전체 종속변수 분포 비율을 학습 및 검증 데이터셋에 반영하여 분할
- 즉, 종속변수의 종류가 a,b,c이고 각각의 분포 비율이 1:1:1이라면 학습 데이터와 검증 데이터의 종속변수 분포도 각각 1:1:1을 따르게 됨
- sklearn.model_selection 패키지의 StratifiedKFold 클래스
- 일반적으로 분류분석에서 사용
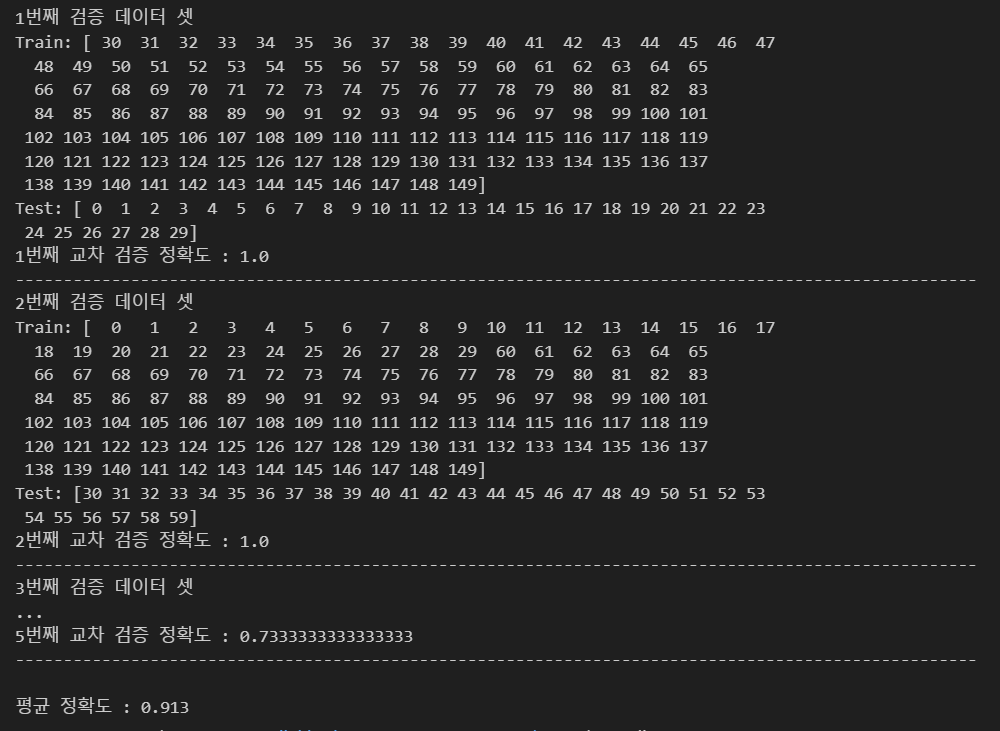
Stratified K-Fold cross validation
※ K-fold 방식 구현코드와 매우 유사함

결과를 통해, 종속변수의 unique값의 개수만큼 같은 비율로 검증데이터를 설정함을 알 수 있음. 그렇기 때문에 분류분석 모델의 검증에 유용할 것임.
3. cross_val_score(), cross_validate()
- sklearn.model_selectioin 패키지의 교차검증 수행 함수
- 분석모델에 따라 교차 검증 방법을 다르게 수행함
▷ 회귀 : KFold 클래스
▷ 분류 : StratifiedKFold 클래스
- 주요 파라미터
- estimator : fit을 구현한 학습 알고리즘 객체
- x : 피쳐 데이터 셋
- y : 레이블 데이터 셋
- scoring : 성능 평가지표 (cross_validate() : 여러 평가지표를 리스트 형태로 전달 가능)
- cv : 교차 검증 폴드 수 (default :5)
cross_val_score()

cross_validation()
dict_keys(['explained_variance', 'r2', 'max_error', 'matthews_corrcoef', 'neg_median_absolute_error', 'neg_mean_absolute_error', 'neg_mean_absolute_percentage_error', 'neg_mean_squared_error', 'neg_mean_squared_log_error', 'neg_root_mean_squared_error', 'neg_mean_poisson_deviance', 'neg_mean_gamma_deviance', 'accuracy', 'top_k_accuracy', 'roc_auc', 'roc_auc_ovr', 'roc_auc_ovo', 'roc_auc_ovr_weighted', 'roc_auc_ovo_weighted', 'balanced_accuracy', 'average_precision', 'neg_log_loss', 'neg_brier_score', 'positive_likelihood_ratio', 'neg_negative_likelihood_ratio', 'adjusted_rand_score', 'rand_score', 'homogeneity_score', 'completeness_score', 'v_measure_score', 'mutual_info_score', 'adjusted_mutual_info_score', 'normalized_mutual_info_score', 'fowlkes_mallows_score', 'precision', 'precision_macro', 'precision_micro', 'precision_samples', 'precision_weighted', 'recall', 'recall_macro', 'recall_micro', 'recall_samples', 'recall_weighted', 'f1', 'f1_macro', 'f1_micro', 'f1_samples', 'f1_weighted', 'jaccard', 'jaccard_macro', 'jaccard_micro', 'jaccard_samples', 'jaccard_weighted'])
▶ 평가 지표 목록 (파라미터로 넣을 수 있음)
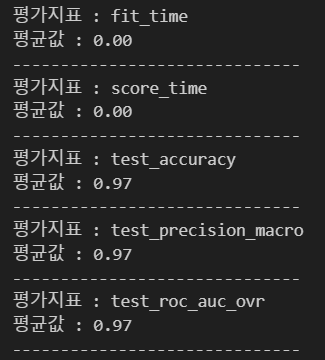
※ scoring에 평가지표 지정하지 않은 경우