[ML] One-hot encoding, Labeling
※ 인코딩 : 명목형 데이터→숫자
: 머신러닝에서 분류 모델을 다루거나, 데이터 분석에서 범주형 데이터 혹은 카테고리컬한 문제를 만단다면, 데이터를 컴퓨터가 인식할 수 있도록 변형해줘야 함.
- 명목형 데이터(순서 의미가 없는 데이터), 유니크 값의 개수가 적은 경우 → 원-핫 인코딩
- 순위형 데이터(순서의 의미가 있는 데이터) → 라벨링
1. One-hot encoding (원-핫 인코딩)
- 0(False),1(True) 즉 바이너리 형태로 만드는 것.
- 이 과정을 거치면 데이터 형태는 0, 1로 이루어졌기 때문에 컴퓨터가 인식하고 학습하기에 용이함. 즉, 범주형 변수를 이진 벡터로 표시함.
- 모든 범주형 변수를 정수인 1과 0의 이진형 벡터로 표시하면 변수를 열거하고, 해당하지 않는 모든 항복은 0으로 , 해당하는 항목은 1로 표시함.
- 입력값 즉, 설명변수는 2차원 데이터여야 함
- 구현 시, 인코딩 결과가 밀집행렬(Dense Matrix)이기 때문에 다시 희소 행렬(Parse Matrix)로 변환해야 함
ex) (unique 값의 개수만큼 컬럼이 생성됨)
| java | python | c | pascal |
| 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 |
● 단점 : 희소벡터
1로 채워진 값은 한 개 뿐이고 나머지 컬럼에 대한 값은 0으로 채워지므로 불필요한 메모리 낭비가 발생함. 그러므로 unique값 즉, 독립변수들이 많아질수록 컬럼 수가 증가하므로 메모리의 낭비도 증가하게 됨.
● 구현 방법
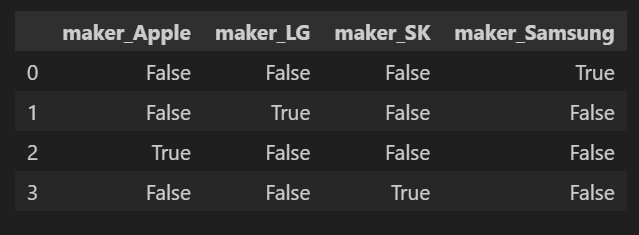
- Pandas : pd.get_dummies (df, columns =[컬럼명,...]) # 컬럼명 지정x => df명_변수명
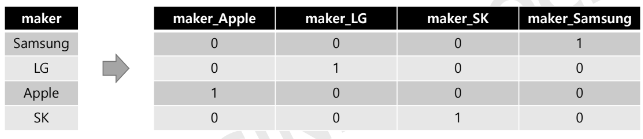
# 방법 1)
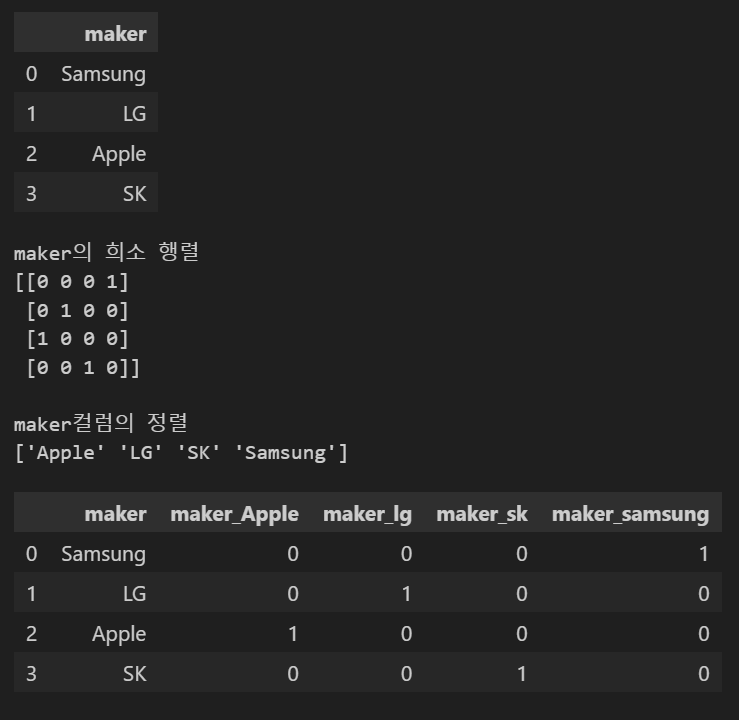
# 방법 2)
- Scikit-Learn : from sklearn.preprocessing import OneHotEncoder
| (0,3) | 1.0 |
| (1,1) | 1.0 |
| (2,0) | 1.0 |
| (3,2) | 1.0 |
※ (행,열) : 튜플의 형태의 좌표로 표시 => 밀집행렬의 형태로 결과 반환됨
※ 원-핫 인코딩의 결과는 희소행렬이기 때문에 메모리 공간 절약을 위해 1값의 위치만 표현

2. Labeling (라벨 인코딩)
: 알파벳 정렬 순서로 숫자를 할당해 주는 것. 즉, 순위 부여
- 명목형 변수 값을 알파벳 정렬 숫자로 할당해 주는 것을 말함
- 단, 라벨 인코딩 수행 시 그 결과가 알파벳 순으로 라벨링 되는 것이고, 그로 인해 랭크된 숫자 정보가 모델에 잘못된 정보를 반영할 수 있음
- 따라서, 명목형 변수는 가급적 원-핫 인코딩으로 처리해주지만 명목형 변수의 범주가 너무 많아 데이터의 컬럼들이 너무 많아진다면 라벨 인코딩을 해줌
| Java | 2 |
| Python | 4 |
| C | 1 |
| Pascal | 3 |
● 구현 방법
- Pandas : df.컬럼명.map(딕셔너리 객체)
map_data = {"Apple":0,"Samsung":1,"LG":2,"SK":3}
df.maker.map(map_data)
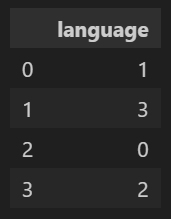
- sklearn : from sklearn.preprocessiong import LabelEncoder
