Python/Pandas
[Pandas] 그룹핑
yeonny_do
2023. 11. 13. 19:09
■ 그룹핑
- 특정 값을 기준으로 몇 개의 그룹으로 분할하여 처리하는 방식
※ 데이터 준비
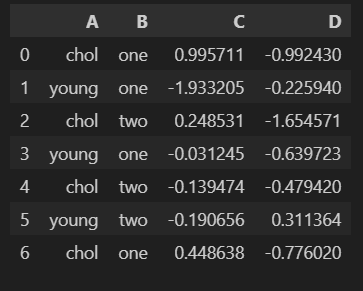
df = pd.DataFrame({'A':['chol','young']*3+['chol'],
'B':['one','one','two','one','two','two','one'],
'C':np.random.randn(7),
'D': np.random.randn(7)})
df
□ 그룹 객체 만들기
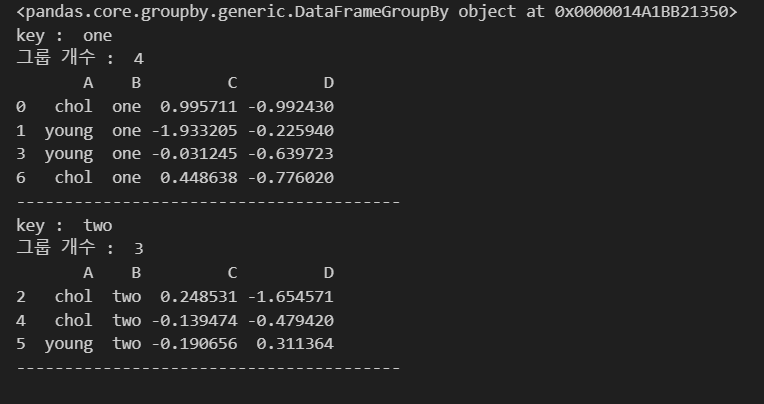
grouped = df.groupby('B')
print(grouped)
for key, group in grouped:
print('key : ',key)
print('그룹 개수 : ',len(group))
print(group.head())
print('-'*40)
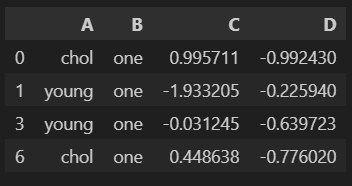
# 특정 그룹만 선택 가능
one_group=grouped.get_group('one')
one_group.head()
□ 그룹 연산
- 그룹별 통계치 구하기 : df.groupby(컬럼명)[컬럼명 목록].통계함수()
- Dataframe의 함수 적용 가능 컬럼들에 대해 그룹별 통계치를 구함
- 통계함수 : sum, mean,std, var, min, max, count, quantil 등
df.groupby('B').sum()
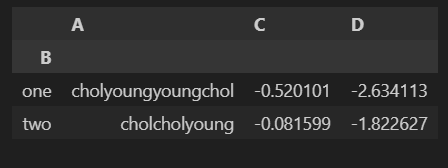
df.groupby('B')[['C','D']].sum()
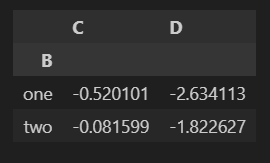
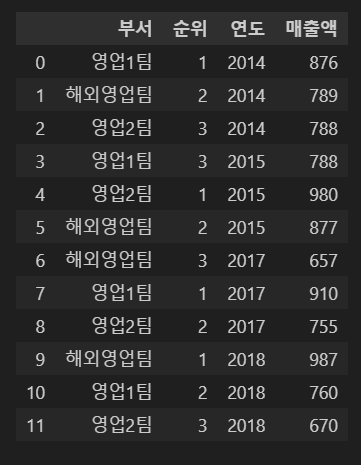
- csv파일에 저장된 데이터 dataframe으로 읽어오기

data = pd.read_csv('sales.csv')
display(data)
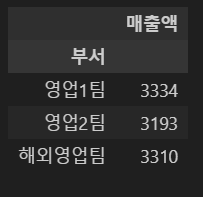
|
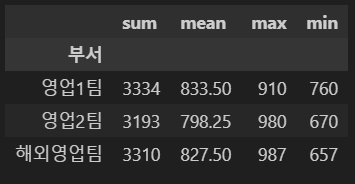
data.groupby('부서')[['매출액']].sum() |
data.groupby('부서')['매출액'].sum() |
 |
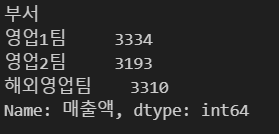 |
※ 왼쪽의 경우, 컬럼 명을 리스트로 전달했으므로 결과값이 dataframe으로 반환되고, 오른쪽의 경우는 Series로 반환됨
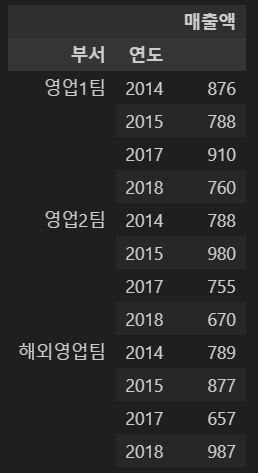
data.groupby(['부서','연도'])[['매출액']].sum()

data.pivot_table(index=['부서','연도'],values='매출액',aggfunc='sum')
※ 위의 그룹함수 사용한 코드와 동일한 결과 반환함
□ Aggregation
: df.groupby(컬럼명)[컬럼명].agg(통계함수1, 통계함수2,...)
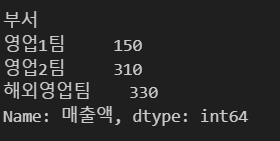
grouped = data.groupby('부서')
def min_max(x):
return x.max()-x.min()
grouped['매출액'].agg(min_max)
※ agg에 사용자 정의 함수도 넣을 수 있음
grouped['매출액'].agg(['sum','mean','max','min'])